Comunicación presentada al II Congreso Ciudades Inteligentes:
Autores
- Inés Huertas, Data Scientist, Datatons
- Carlos Izquierdo, Arquitecto Big Data, Datatons
- Jorge Vidal, Arquitecto Big Data, Datatons
Resumen
Programar el comportamiento de los sensores dentro de Smart Cities no aporta valor añadido si no una monitorización de eventos, para que este proceso sea un proceso de aprendizaje automático y semi-autónomo necesitamos herramientas y plataformas que puedan almacenar y manipular estos datos recogidos. Mostraremos la aplicación de tecnologías de Big Data que permiten almacenar, manipular y procesar estos datos de una manera sencilla y eficiente.
Introducción
El objetivo de las Smart Cities abarca diferentes áreas dentro del contexto de la convivencia urbana, impulsando el crecimiento económico sostenible y la prosperidad para sus ciudadanos. Para conseguir este fin se requiere disponer de las herramientas necesarias para capturar la información que permita parametrizar cada una de las áreas que aplican.
Estas áreas tienen diferentes naturalezas como son la gestión y planificación de recursos, despliegue de infraestructuras y servicios al ciudadano, pero todas ellas tienen en común la obtención de información sobre lo qué está ocurriendo para desencadenar una acción si es necesario. Por ejemplo, si es un día de lluvia puede que no sea necesario activar el regadío de los parques y zonas ajardinadas del área correspondiente o dependiendo del tráfico puntual en una zona puede que sea necesario alterar las rutas por defecto.
La obtención de estos datos es básica y primordial para articular la operativa y logística dentro de las Smart Cities, pero ¿para qué nos sirven estos datos además de contrastarlos frente a unos umbrales ya definidos? O mejor planteado, ¿cómo definimos estos umbrales? Existen muchas acciones que podemos definir de forma lógica o intuitiva y que podemos programar de manera constante en el tiempo, pero existe mucha información que podemos extraer de esta toma de medidas para enriquecer y automatizar de manera dinámica la gestión de estos servicios para conseguir un resultado óptimo. Para ello necesitamos tecnologías que nos permitan almacenar y tratar estos volúmenes de datos como plataformas Big Data y aplicar sobre las mismas metodologías de analítica predictiva.
Caso de uso
Un ejemplo sobre la diferencia entre programar unos umbrales fijos y obtenerlos mediante sensorización sería la implementación de un proyecto similar al de “luz inteligente” en Amsterdan. Este proyecto consiste en un alumbrado público que permite ajustar la iluminación en función de la situación o necesidad del lugar donde se despliega, permitiendo que las autoridades puedan adaptar la intensidad de la luz según el clima o cambiar el color de dicha luz, de forma que el alumbrado consuma menos energía que en las ciudades convencionales.
Para implementar este caso de una forma centralizada podría definirse a priori en función del día del año y la hora del día para programar la hora de encendido, hora de apagado, etc. Obtendríamos un gráfico de horas de encendido fijo por área para todo el año como el siguiente:
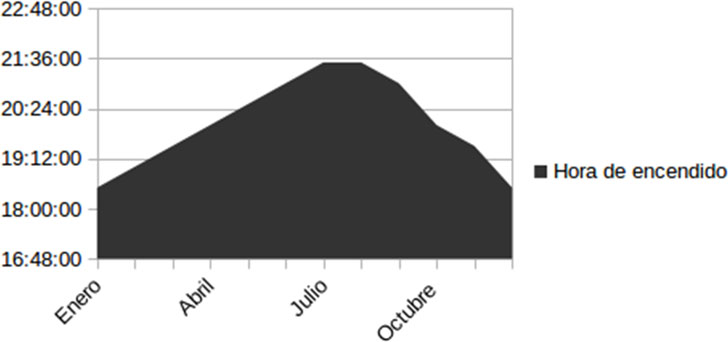
En cambio, esta implementación está dejando de lado información que podría enriquecer y hacer más acertado el encendido/apagado de luces permitiendo adelantarnos y prever el nivel de luz necesaria para tener una visibilidad óptima. Por ejemplo, podemos disponer de otros datos (obtenidos a partir de sensores) que afecten a la visibilidad de una zona y nos permitan predecir a partir de ellos qué nivel de luz se va a necesitar en las próximas horas:

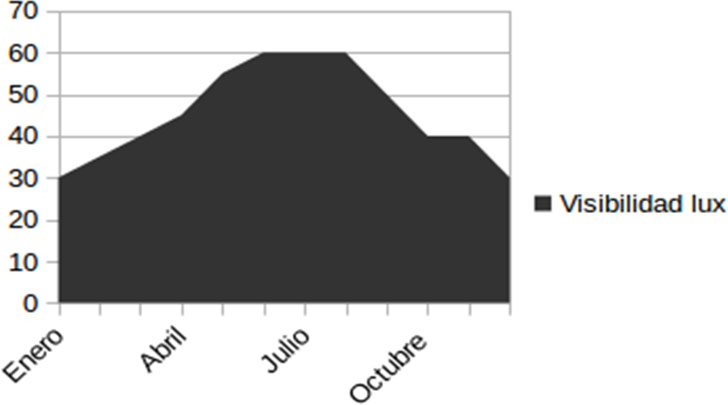
Estos datos históricos podrían ser almacenados para realizar analíticas predictivas que por un lado intenten anticipar cuál va a ser el valor para cada uno de los sensores en las próximas horas y por otro obtuvieran la relación existente para obtener el nivel de visibilidad a partir de las variables de polución y lluvias.
Realizar un forecast sobre las variables de polución y de predicción de lluvias para el mes de enero y por otro, analizar y caracterizar la relación a partir de la cual podemos estimar el valor de luminosidad a partir de las variables de polución y lluvias:
Luminosidad = f (Polución, Lluvias)
Estimación de luminosidad a partir de predicción de lluvias y polución en el mes de Enero:
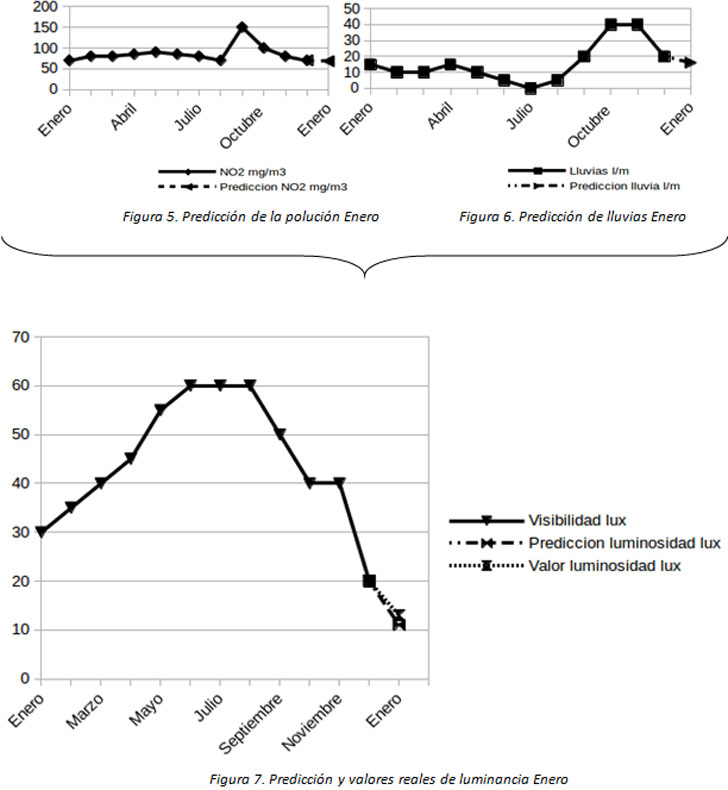
Una vez obtenida esta relación, aplicar para obtener los valores futuros de luminosidad a partir de la estimación calculada para las otras dos variables dependientes.
Con la estimación de los valores de predicción de la polución y las lluvias podemos obtener una estimación del nivel de intensidad de luz esperado y dimensionar encendido por áreas en función de este valor de antemano.
Para poder realizar este tipo de automatizaciones para extracción de información, almacenamiento y procesamiento de datos de sensores necesitamos por un lado poder almacenarlos en algún sitio donde posteriormente podamos llevar a cabo los procesados.
Las tecnologías clásicas de bases de datos pueden resultar costosas y/o ineficientes para la operativa necesaria, incluso ya no solo observando el punto del almacenamiento sino también el del procesado.
Para poder realizar analíticas fiables y acertadas se requiere de grandes volúmenes de datos, en nuestro caso de histórico de registros almacenados, a mayor número de registros de histórico almacenados, mejor entrenado estará nuestro algoritmo y mayor probabilidad de acierto obtendremos en nuestras predicciones. Para solventar este tipo de necesidades nacen las plataformas de Big Data, que permiten escalar de manera muy sencilla, almacenar y procesar grandes cantidades de datos.
Hay que tener en cuenta el tipo de dato que vamos a utilizar, para hacernos una idea en un prototipo y volumen de datos generados por entornos sensorizados, por ejemplo a partir del caso de sensorizar un conjunto de hospitales en USA dentro de un proyecto de edificios inteligentes, en este caso se plantearon sensorizar 170 hospitales con los siguientes datos:

Manejar y procesar 16.5TB de datos con agilidad y en tiempos aceptables es una tarea para plataformas de Big Data. Este es un ejemplo del volumen de datos que nos vamos a encontrar en nuestras Smart Cities y vamos a tener que aprender a manipular y usar para extraer información de valor de nuestros propios datos.
Mencionar también que se pueden integrar con otras fuentes de datos ya sean sensorizadas o fuentes externas como APIs de datos para enriquecimiento del dato, redes sociales, etc.
Descripción de la plataforma
La plataforma propuesta consta de un core basado en tecnologías Big Data sobre el cual se almacenan y procesan los datos recopilados de los sensores usando herramientas como R o Spark.
Por un lado, se deberá estar constantemente ejecutando con los datos actualizados los nuevos parámetros que permitan realizar la analítica predictiva mientras que por otro se tendrá que dar una respuesta a un valor recibido por un sensor.
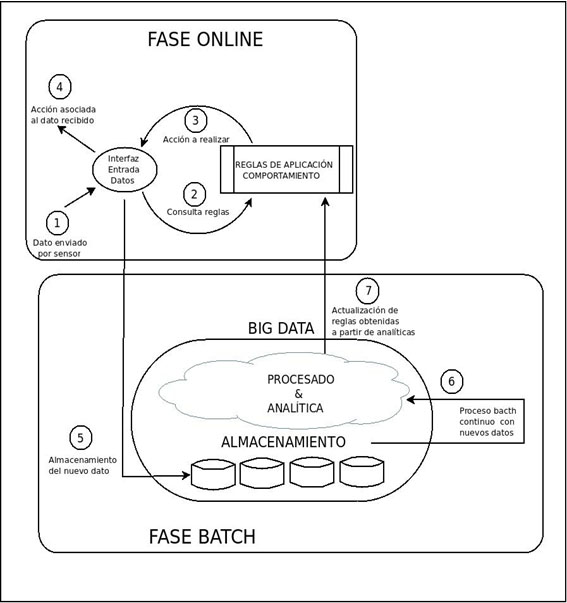
Con este tipo de arquitectura podemos dar servicio en tiempo real a los eventos que son enviados por los sensores, posteriormente ese dato no se “tira” si no que se almacena para generar las siguientes reglas de comportamiento en el proceso batch que no puede ejecutar en tiempo real.
La plataforma consta de dos fases:
1. Fases online: Para por un lado dar respuesta online en función de los datos recibidos.
- Recepción del evento
- Aplicación de reglas calculadas en proceso batch
- Evaluación tipo de acción tras recepción del dato según reglas de comportamiento
- Envío de acción asociada
2. Fases de Batch: En la que se realizan todos los cálculos y algoritmos necesarios y se actualizan las reglas a aplicar en la parte online con los datos almacenados.
- Ingesta del dato a almacenamiento
- Procesado del nuevo conjunto de datos
- Actualización de reglas de comportamiento calculadas con los nuevos datos
El escalado y capacidad de estas plataformas es muy sencillo y barato, soluciones actuales como Hadoop de software libre permiten su implantación sin coste por licenciamiento.
Conclusiones
Programar el comportamiento de los sensores dentro de nuestra Smart City no nos da ningún valor de inteligencia añadido, para que este proceso sea un proceso de aprendizaje automático y semi-autónomo necesitamos herramientas y plataformas que nos permitan almacenar y manipular estos datos recogidos.
Con este tipo de arquitectura basadas en Big Data abarcamos todas las necesidades de acceso a los datos, pudiendo integrar diferentes fuentes de sensores, datos estructurados y no estructurados y combinarlos para obtener una visión global de lo que está ocurriendo en nuestra ciudad.
Un paso más allá es el que mencionamos con integración de otras fuentes de datos que nos permitan estudiar incluso el llamado “citizen care”, es decir, la percepción que están teniendo la ciudad y los ciudadanos a través de redes sociales, presencia o no en función de conexiones a wifis públicas, inferencias a partir de datos del INE, etc.